Quantum AI - Part 4 - The key role of DataOps
This article is the fourth of our quantum AI column. Previously, we have seen that:
- Chapter 1: quantum computing will significantly accelerate the execution of some machine learning algorithms and cryptographic processing;
- Chapter 2: quantum phenomena (superposition and entanglement) responsible for parallel computing can only be exploited for a very short time under strict isolation conditions (decoherence problem);
- Chapter 3: Despite all its promises, quantum AI will probably not be able to give birth to an artificial consciousness or a so-called strong AI;
In this new chapter, I want to share my point of view on the theoretical implementation of a quantum production device in a company. This can for example be a decision-making (BI) or machine learning process based on an infrastructure mixing both conventional and quantum machines. The interest being, of course, to take advantage of quantum processors to solve problems that are insoluble today, regardless of the servers used. Nevertheless, it must be noted that such a device cannot be simply done without resorting to a DataOps approach.
Infrastructures going hybrid
The initial problem is that when real quantum computers will see the light of day, it is very likely that they will be in the hands of big American players such as IBM, Google or Microsoft, for the simple reason that these new equipment will be out of price... So whatever your urbanization policy, you will have to deal with the cloud to experiment with calculations on virtual quantum machines. In the absence of a "full cloud" policy, it will therefore be highly desirable to be able to rely on hybrid infrastructures (cloud and on-premise) - or multi-cloud if necessary - to limit the risk of dependence on one provider.
Today, we are already encountering similar problems of resource allocation. For example, one may want to provision a cloud experimentation environment (to test cognitive services, for example) and maintain an on-premise production environment. However, while operating HPC servers in a cluster is now made easier thanks to container orchestrators, of which Kubernetes is the most emblematic current representative, the parallel operating of several disjointed and heterogeneous clusters remains extremely difficult. The complexity is to be able to use different environments without losing the common thread of your analytical project, including the data location, the continuity of processing pipelines, the logs centralization...
We are dealing here with a well-known problem across the Atlantic. The agility of the infrastructures and the orchestration of processing on heterogeneous computer grids are some of the main issues that the DataOps addresses by long-term.
In the rest of this article, I will call "supercluster" a logical set of heterogeneous and hybrid clusters. For example, this can be the bundling of an on-premise environment running a commercial distribution of Hadoop or Kubernetes, coupled with an AKS cluster in Azure or and an EKS cluster in AWS or GKE in Google Cloud.
What is DataOps?
Before continuing on the management of superclusters, it is necessary to define the term DataOps, which is quite rare in Europe and more particularly in France. DataOps is an organizational and technological scheme inspired by DevOps. It is about bringing agility, automation and control between the various stakeholders of a data project, namely the IT department (IT Ops, developers, architects), the Data Lab/Team (data product owner, data scientists, engineers, stewards) and the business lines.
The aim is to operationalize analytical processes by making the most of the diversity of the big data technological ecosystem and the multiplicity of skills of each stakeholder. To sum up, I believe there are 9 functional pillars within the scope of a DataOps approach:
These principles apply to each step of the data life cycle (also known as the data value chain or data pipeline).

The DataOps approach is therfore vast and complex, but it is the only way to create a sufficient level of abstraction to orchestrate the analytical processing in a supercluster, as summarized in the following diagram we will go through in the rest of this article:

Step 1 - Building a pipeline by abstraction levels
The DataOps interface (vertical block in the center) has four technology components: the CI/CD tooling, the shared files and artifacts, the data virtualizer, and the meta-orchestrator. There are of course other aspects such as security or metrology but these will not be elaborated in this article. The first step in implementing this interface is to split the analytical process (pipeline) into different independent links roughly corresponding to the data life cycle: extraction, cleaning, modeling...
This approach has a double interest:
- First, it allows to take advantage of different programming languages (a fortiori with different frameworks) according to the considered link (we do not use the same tools in ETL as in machine learning for example);
- Secondly, this splitting makes it possible to optimize the load balancing (which we will see in step 4).
But this splitting does not stop there: even within a specific activity (a link), it is recommended to split its code according to the different levels of functional abstraction. You can imagine a multi-stage pipeline: the first pipeline consists of business bricks (eg "Segment customers") and each of these bricks uses a sub-pipeline that connects steps a little more elementary (ex: "Detect missing values", "Execute K-Means", etc.) and so on. Below is an example of pipeline and sub-pipelines. Note that the higher the pipeline, the more abstract it is; each dark cell uses a lower abstraction sub-pipeline.

This breakdown into abstraction levels can also be done directly in the codes (through functions and classes) rather than in the pipeline. But it is important to keep some of the abstraction in the pipeline directly as this will allow to isolate and orchestrate algorithm fragments that may or may not benefit from quantum acceleration (see step 4).
Indeed, it is important to remember that only certain steps of an algorithm can benefit from quantum computing capabilities (see the first article of quantum IA). These are generally matrix inversions, global extremum searches, modular computations (at the basis of cryptography), etc. Beyond knowing whether or not quantum can speed up some processing, this code splitting mainly allow to reduce the cloud bill by limiting the use of quantum VMs to the strict minimum (because their hourly cost will probably make people grind their teeth).
Digression - An example of a classical algorithm partially converted to quantum
When working with a DBN (Deep Belief Network), it is possible to isolate the unsupervised pre-training phase of RBM stacks and the "fine-tuning" phase. Indeed, some researchers have been interested in a quantum acceleration of the sampling steps in the case of a convolutional deep belief network (yes, the name is quite barbaric). The goal is to compare the performance of quantum sampling compared to classical models such as the CD (Contrastive Divergence) algorithm. This study shows that quantum can boost the pre-training phase, but not the discrimination phase! That is why it is important to split properly the steps of the algorithms, to avoid the unnecessary use of a quantum machine on classical computations that are long and non-transposable in a quantum-way.
Moreover, beyond price optimization, splitting codes into abstraction levels is also and above all an essential methodology in script writing. An interesting article on this subject shows that abstraction management (consisting of distinguishing the "what" from the "how") is a good development practice that encompasses many others.
Step 2 - Integration with repository and CI/CD tools
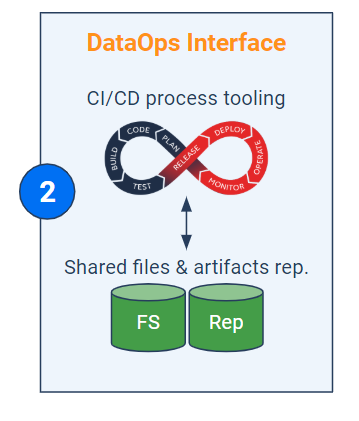 Now that the codes (and other artifacts) in the main pipeline are cleverly split by abstraction levels, they should be centralized in the repository. This approach is usually made along with code standardization. The goal is to be able to reuse them easily in different contexts.
Now that the codes (and other artifacts) in the main pipeline are cleverly split by abstraction levels, they should be centralized in the repository. This approach is usually made along with code standardization. The goal is to be able to reuse them easily in different contexts.
The generic and repeatable property of a code can be obtained with a double "variabilization". The first is an intuitive generalization of the code by creating variables related to data processing (through classes, methods, functions ...). The second is the use of environment variables, meaning that the code is dynamically adjusted according to the environment (in terms of infrastructure) in which it runs. For example, the variable "password" can have multiple values, each of which is linked to a specific cluster.
As for automating the testing and deployment of these scripts, the DataOps solution can either integrate CI/CD features, or connect to existing tools such as Maven, Gradle, SBT, Jenkins/JenkinsX, etc. These tools collect the centralized binaries in the repository to integrate them into the processing pipeline. The codes then become "jobs" that will run in dedicated clusters. The pipeline must finally be able to historize the versions of the jobs that compose the pipeline, to keep track of all previous deliveries and possibly proceed with "rollbacks".
Step 3 - Data virtualization

The penultimate step is the storage abstraction. Indeed, since the purpose is to leverage scattered infrastructures - which already requires a huge programming effort to make the codes generic - it is preferable not to have to take into account the exact location of the data or not to have to replicate them for each processing.
This is typically the role of a data virtualizer that allows an implicit connection to intrinsically different storage sources and eases memory management to avoid futile data replication. In addition, data virtualization solutions provide an undeniable competitive advantage in the implementation of cross-infrastructure data governance. By this I mean the implementation of a single and cross-repository with metadata and authorizations management.
The data virtualizer acts at the time of data reading (to perform processing) and also at the end of the chain to write the intermediate or final results in a local or remote database (or cluster).
Step 4 - Advanced load balancing
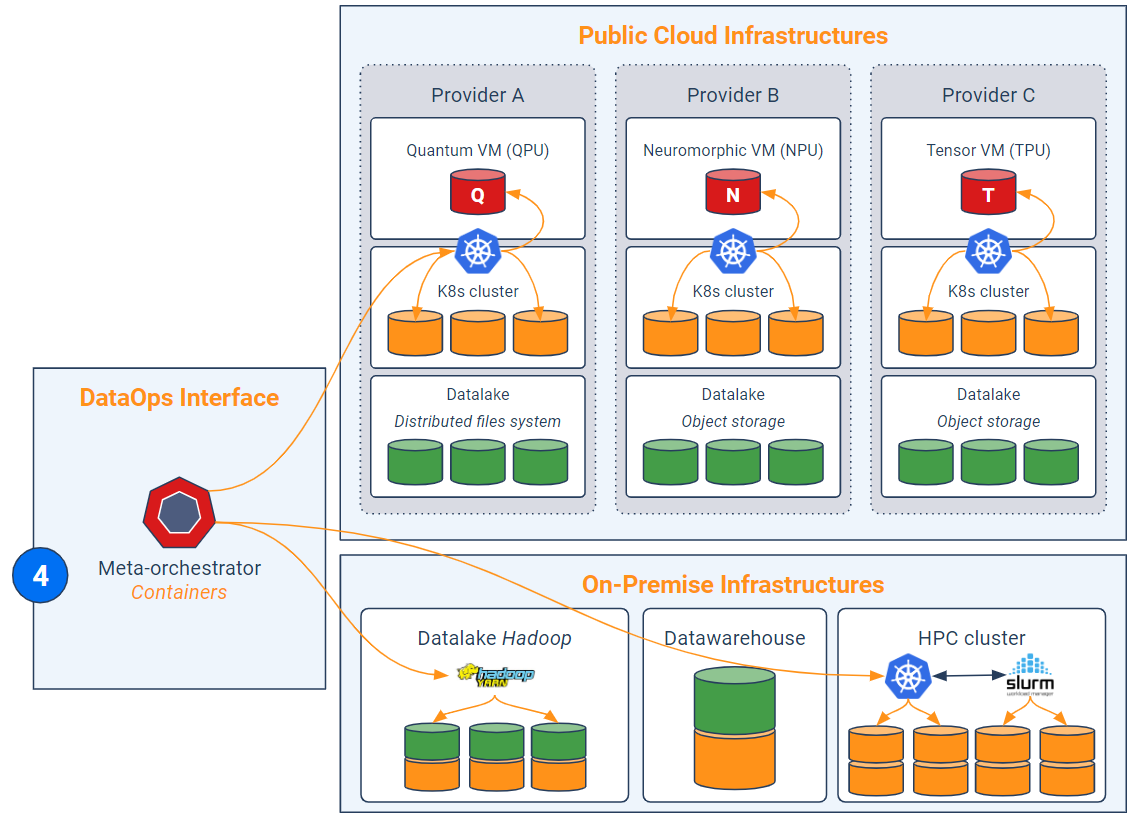
Now that all the data is made available (thanks to the virtualizer) and the codes are standardized and broken down into coherent functional units, the idea is to orchestrate the associated processing within the supercluster. In other words, we want now to execute the algorithmic containers in the appropriate clusters.
Each cluster is governed by a solution acting as a task scheduler/dispatcher and as a container and physical resource manager (like Kubernetes). Today, all cloud providers offer a Kubernetes-as-a-service in their virtual clusters.
The DataOps solution must go one step further and play the role of "meta-orchestrator". The latter aims at balancing jobs among the underlying orchestrators (Kubernetes) of each cluster. The meta-orchestrator is therefore an additional abstraction layer to Kubernetes. When a quantum acceleration is required, the meta-orchestrator is in charge of redirecting the algorithmic container to one of the Kubernetes orchestrating the quantum VMs. Thus, the meta-orchestrator ensures that only the relevant jobs are routed to the quantum VMs while the others can run on-premise or on cloud clusters composed of traditional VMs.
As for HPC clustering issues, it is highly likely that the development of interfaces between Kubernetes and computer grid schedulers (like Slurm, IBM Spectrum LSF) will continue. In which case, the meta-orchestrator will go either through Kubernetes (in the ideal case) or through the HPC grid scheduler to balance the processing load.
In summary, the rise of quantum machines in the cloud will encourage companies to optimize the way they orchestrate their analytic and hybrid environments. This is a matter of data sovereignty, vendor dependence and cost (quantum computing is likely to be very expensive). The DataOps interface (which can be a unified software solution), is in particular composed of four elements: a CI/CD tool, a repository of shared files and scripts, a data virtualizer and a meta-orchestrator (in practice, a security device and a global monitoring system must also be added). The interest is threefold: to simplify the management of decentralized data, to automate the deployment of complex pipelines and to orchestrate the routing of certain massive codes (compatible with quantum formalism) to Kubernetes clusters equipped with quantum VMs. Companies would thus be able to govern their data in hybrid mode, to optimize load balancing and to control their costs (especially the cloud bill) by soliciting the right clusters at the right time, especially when it comes to using HPC servers (GPU, TPU, NPU, QPU, etc.).
____
This article is part of a column dedicated to quantum AI. Find all posts of the same theme:
Part 1 – Ending impotence!
Part 2 – The die has been cast!
Part 3 – Rise of the AIs
Part 4 – The key role of DataOps
A. Augey
Also published in Saagie's company blog: https://www.saagie.com/blog/quantum-ai-part-4-the-key-role-of-dataops/


