IA Quantique - Partie 4 - Le rôle clé du DataOps

- Partie 1 : l’informatique quantique permettra d’accélérer sensiblement l’exécution de certains algorithmes de machine learning et de traitements cryptographiques ;
- Partie 2 : les phénomènes quantiques (superposition et intrication) responsables de la parallélisation intrinsèque des calculs ne peuvent être exploités que pendant une très courte période dans des conditions d’isolation strictes (problème de décohérence) ;
- Partie 3 : malgré toutes ses promesses, l’IA quantique ne sera probablement pas en mesure de donner naissance à une conscience artificielle ou une prétendue IA forte ;
Dans ce nouveau chapitre, je souhaite vous partager mon point de vue sur la mise en oeuvre théorique d’un dispositif quantique de production en entreprise. Cela peut par exemple être un processus décisionnel (BI) ou de machine learning reposant sur une infrastructure composée à la fois de machines classiques et quantiques. L’intérêt étant bien entendu de tirer parti de processeurs quantiques pour résoudre des problèmes aujourd’hui insolubles, quels que soient les serveurs utilisés. Néanmoins, force est de constater qu’un tel dispositif ne pourra se faire simplement sans avoir recours à une démarche DataOps. Décryptage.
Vers une hybridation inéluctable des infrastructures
Le problème initial est que lorsque de vrais ordinateurs quantiques verront le jour, il est fort probable que ceux-ci soient entre les mains de grands acteurs américains tels que IBM, Google ou Microsoft, pour la simple et bonne raison que ces nouveaux équipements seront hors de prix… Donc quelle que soit votre politique d’urbanisation, vous devrez composer avec le cloud pour expérimenter des calculs sur machines virtuelles quantiques. A défaut de politique “full cloud”, il sera donc fortement souhaitable de pouvoir s’appuyer sur des infrastructures hybrides (cloud et on-premise) - ou multi-clouds à la rigueur - pour limiter le risque de dépendance à un fournisseur.
Aujourd’hui, on rencontre déjà des problématiques similaires de répartition des ressources. Par exemple, on peut vouloir provisionner un environnement d’expérimentation dans le cloud (pour tester des services cognitifs par exemple) et conserver un environnement de production on-premise. Cependant, si exploiter des serveurs HPC (High Performance Computing) dans un cluster est désormais facilité grâce aux orchestrateurs de conteneurs, dont Kubernetes est le plus emblématique représentant actuel, l’exploitation en parallèle de plusieurs clusters disjoints et hétérogènes s’avère extrêmement périlleuse. La complexité est de pouvoir utiliser les différents environnements sans perdre le fil conducteur de votre projet analytique, à savoir la localisation des données, la continuité des pipelines de traitements, la centralisation des logs…
On touche ici à un problème bien connu outre-Atlantique : l’agilité des infrastructures et l’orchestration des traitements sur des grilles informatiques hétérogènes. C’est d’ailleurs l’un des principaux enjeux qu’adresse le DataOps à long-terme.
Dans la suite de cet article, j’appellerai “supercluster” un ensemble logique de clusters hétérogènes et hybrides. Par exemple, cela peut-être le regroupement d’un environnement on-premise fonctionnant sous une distribution commerciale de Hadoop ou Kubernetes, couplée à cluster AKS dans Azure et à un cluster EKS dans AWS ou encore GKE dans Google Cloud.
Aujourd’hui, on rencontre déjà des problématiques similaires de répartition des ressources. Par exemple, on peut vouloir provisionner un environnement d’expérimentation dans le cloud (pour tester des services cognitifs par exemple) et conserver un environnement de production on-premise. Cependant, si exploiter des serveurs HPC (High Performance Computing) dans un cluster est désormais facilité grâce aux orchestrateurs de conteneurs, dont Kubernetes est le plus emblématique représentant actuel, l’exploitation en parallèle de plusieurs clusters disjoints et hétérogènes s’avère extrêmement périlleuse. La complexité est de pouvoir utiliser les différents environnements sans perdre le fil conducteur de votre projet analytique, à savoir la localisation des données, la continuité des pipelines de traitements, la centralisation des logs…
On touche ici à un problème bien connu outre-Atlantique : l’agilité des infrastructures et l’orchestration des traitements sur des grilles informatiques hétérogènes. C’est d’ailleurs l’un des principaux enjeux qu’adresse le DataOps à long-terme.
Dans la suite de cet article, j’appellerai “supercluster” un ensemble logique de clusters hétérogènes et hybrides. Par exemple, cela peut-être le regroupement d’un environnement on-premise fonctionnant sous une distribution commerciale de Hadoop ou Kubernetes, couplée à cluster AKS dans Azure et à un cluster EKS dans AWS ou encore GKE dans Google Cloud.
Qu’est-ce que le DataOps ?
Avant de continuer sur la gestion des superclusters, il est nécessaire de définir le terme DataOps qui est somme toute assez peu répandu en Europe et plus particulièrement en France. Le DataOps est un schéma organisationnel et technologique s’inspirant du DevOps. Il s’agit d’amener de l’agilité, de l’automatisation et du contrôle entre les différentes parties prenantes d’un projet data, à savoir la DSI (exploitants des SI, développeurs, architectes), le pôle Data (data product owner, data scientists, engineers, stewards) et les métiers.
La finalité est bien d’industrialiser les processus analytiques en exploitant au mieux la diversité du vaste écosystème technologique du big data et la multiplicité des compétences de chaque acteur. En synthèse, il existe selon moi 9 piliers fonctionnels dans le périmètre d’une démarche DataOps :
La finalité est bien d’industrialiser les processus analytiques en exploitant au mieux la diversité du vaste écosystème technologique du big data et la multiplicité des compétences de chaque acteur. En synthèse, il existe selon moi 9 piliers fonctionnels dans le périmètre d’une démarche DataOps :

Ces principes s’appliquent à chacune des étapes du cycle de vie de la donnée (aussi connue sous le nom de chaîne de valeur de la donnée ou data pipeline).
L’approche DataOps est donc vaste et complexe, mais elle seule permet d’instaurer un niveau d’abstraction suffisant pour orchestrer les traitements analytiques dans un supercluster, comme le résume le schéma suivant que nous allons parcourir dans la suite de cet article :
L’approche DataOps est donc vaste et complexe, mais elle seule permet d’instaurer un niveau d’abstraction suffisant pour orchestrer les traitements analytiques dans un supercluster, comme le résume le schéma suivant que nous allons parcourir dans la suite de cet article :

Étape 1 - Construction d’un pipeline par niveaux d’abstraction
L’interface DataOps (bloc vertical au centre) comprend - entre autres - quatre volets technologiques : l’outillage CI/CD, les fichiers et artefacts partagés, le virtualisateur de données et le méta-orchestrateur. Il y a évidemment d’autres aspects tels que la sécurité ou la métrologie mais ces derniers ne seront pas élaborés dans cet article. La première étape d’implémentation de cette interface consiste à découper le processus analytique (pipeline) en différents maillons indépendants correspondant grossièrement au cycle de vie de la donnée : extraction, nettoyage, modélisation…
Cette approche a un double intérêt :
Mais ce découpage ne s’arrête pas là : même au sein d’une activité spécifique (un maillon), il est recommandé de découper son code selon les différents niveaux d’abstraction fonctionnelle. Cela revient à imaginer un pipeline à plusieurs étages : le premier pipeline est constitué de briques métiers (ex : “segmenter les clients”) et chacune de ces briques fait appel à un sous-pipeline qui enchaîne des étapes un peu plus élémentaires (ex : “détecter les valeurs manquantes”, “exécuter une K-Means”, etc.) et ainsi de suite. Ci-dessous un exemple de pipeline et sous-pipelines. A noter que : plus le pipeline est haut, plus il est abstrait ; chaque cellule sombre fait appel à un sous-pipeline d’abstraction plus basse.
Cette approche a un double intérêt :
- Premièrement, cela permet de tirer profit de différents langages de programmation (a fortiori avec des frameworks différents) en fonction du maillon considéré (on n’utilise pas les mêmes outils en ETL qu’en machine learning par exemple) ;
- Deuxièmement, ce découpage permet d’optimiser la répartition de charges (ce que nous verrons dans l’étape 4).
Mais ce découpage ne s’arrête pas là : même au sein d’une activité spécifique (un maillon), il est recommandé de découper son code selon les différents niveaux d’abstraction fonctionnelle. Cela revient à imaginer un pipeline à plusieurs étages : le premier pipeline est constitué de briques métiers (ex : “segmenter les clients”) et chacune de ces briques fait appel à un sous-pipeline qui enchaîne des étapes un peu plus élémentaires (ex : “détecter les valeurs manquantes”, “exécuter une K-Means”, etc.) et ainsi de suite. Ci-dessous un exemple de pipeline et sous-pipelines. A noter que : plus le pipeline est haut, plus il est abstrait ; chaque cellule sombre fait appel à un sous-pipeline d’abstraction plus basse.

Ce découpage en niveaux d’abstraction peut également s’opérer directement dans les codes (via des fonctions et classes) plutôt que dans le pipeline. Mais il est important de garder un certain découpage dans le pipeline directement car cela permettra d’isoler et d’orchestrer les fragments d’algorithmes pouvant bénéficier ou non d’une accélération quantique (cf. étape 4).
En effet, il faut bien se remémorer que seules certaines étapes d’un algorithme peuvent bénéficier des apports de l’informatique quantique (cf. premier article de l’IA quantique). Il s’agit généralement d’inversion de matrices, de recherche d’extremum global, de calculs modulaires (à la base de la cryptographie), etc. Au-delà de savoir si la quantique peut ou ne peut pas accélérer certains traitements, ce découpage des codes permet surtout de réduire la facture cloud en limitant l’utilisation de VM quantiques au strict minimum (car leur coût horaire fera probablement grincer des dents).
En effet, il faut bien se remémorer que seules certaines étapes d’un algorithme peuvent bénéficier des apports de l’informatique quantique (cf. premier article de l’IA quantique). Il s’agit généralement d’inversion de matrices, de recherche d’extremum global, de calculs modulaires (à la base de la cryptographie), etc. Au-delà de savoir si la quantique peut ou ne peut pas accélérer certains traitements, ce découpage des codes permet surtout de réduire la facture cloud en limitant l’utilisation de VM quantiques au strict minimum (car leur coût horaire fera probablement grincer des dents).
Digression - Un exemple d’algorithme classique partiellement converti en quantique
Dans le cadre du DBN (réseau de croyance profonde), on peut isoler les étapes de pré-entraînement non supervisé des empilements de RBM et la phase de “fine-tuning” (ajustement fin). En effet, certains chercheurs se sont intéressés à une accélération quantique des étapes d’échantillonnage dans le cas d’un réseau convolutif de croyance profonde [1] (oui, le nom est assez barbare). Le but étant de comparer la performance de l'échantillonnage quantique comparativement à des modèles classiques tels que l’algorithme CD (‘contrastive divergence’). Cette étude montre que la quantique permet de booster la phase de pré-entraînement, mais pas la phase de discrimination ! D’où l’importance de bien décomposer les étapes de l’algorithme, pour éviter de solliciter inutilement une machine quantique sur des calculs classiques longs et non transposables quantiquement parlant.
D’ailleurs, au-delà de l'optimisation tarifaire, le fractionnement des codes en niveaux d’abstraction est aussi et surtout une méthodologie essentielle dans la rédaction des scripts. Un article intéressant sur ce sujet [2] qui montre que la gestion de l’abstraction (consistant à distinguer le “quoi” du “comment”) est une bonne pratique de développement qui en englobe beaucoup d’autres.
Étape 2 - Intégration aux dépôts et outils de CI/CD
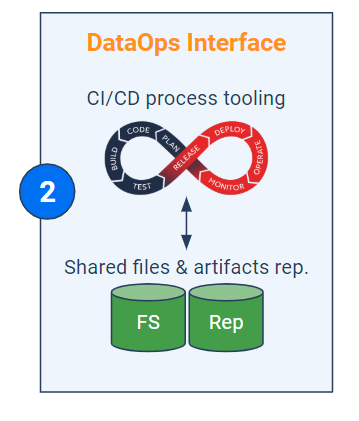
Maintenant que les codes (et autres artefacts) du pipeline général sont judicieusement fractionnés par niveaux d’abstraction, il convient de les centraliser dans le dépôt. Cette démarche s’accompagne habituellement d’une standardisation des codes. Le but est de pour pouvoir les réutiliser facilement dans des contextes différents.
Le caractère générique et répétable d’un code peut s’obtenir au moyen d’une double “variabilisation”. La première est une généralisation intuitive du code en créant des variables relatives aux traitements des données (via des classes, méthodes, fonctions...). La seconde est la création de variables d’environnement, c’est-à-dire que le paramétrage du code s’effectue dynamiquement en fonction de l’environnement (au sens infrastructure) dans lequel il s’exécute. Par exemple, la variable “mot_de_passe” peut comporter plusieurs valeurs, chacune d’elles étant liée à un cluster spécifique.
Quant à l’automatisation des tests et du déploiement de ces scripts, la solution de DataOps peut soit intégrer des fonctionnalités de CI/CD, soit se connecter aux outils existants tels que Maven, Gradle, SBT, Jenkins/JenkinsX, etc. Ces derniers viennent récupérer les binaires centralisés dans le dépôt pour les intégrer dans le pipeline de traitement. Les codes deviennent alors des “jobs” qui s'exécuteront dans des clusters dédiés. Le pipeline doit enfin pouvoir historiser les versions des scripts et jobs qui le composent pour conserver une trace de toutes les livraisons précédentes et éventuellement procéder à des “rollbacks”.
Étape 3 - Virtualisation des données

Avant-dernière étape, l’abstraction du stockage. En effet, dans la mesure où la finalité est d’exploiter des infrastructures éparpillées - ce qui demande déjà un énorme effort de programmation pour rendre les codes génériques - il est préférable de ne pas devoir tenir compte de la localisation exacte des données ni de devoir les répliquer à chaque traitement.
C’est typiquement le rôle d’un virtualisateur de données qui permet, généralement via des requêtes SQL ou REST, une connexion implicite à des sources de stockage intrinsèquement différentes en évitant le déplacement ou la recopie futile des données. Par ailleurs, les solutions de virtualisation des données apportent de fait un avantage concurrentiel indéniable dans la mise en oeuvre d’une gouvernance des données cross-infrastructures. J’entends par là la mise en oeuvre d’un référentiel transverse et unique avec gestion des métadonnées et des habilitations.
Le virtualisateur de données intervient au moment de la lecture des données (pour effectuer les traitements) et également en bout de chaîne pour écrire les résultats intermédiaires ou finaux dans une base (ou un cluster) locale ou distante.
Étape 4 - Répartition avancée de la charge

Maintenant que toutes les données sont mises à disposition (via le virtualisateur) et que les codes sont standardisés et découpés en unités fonctionnelles cohérentes, l’idée est d’orchestrer les traitements associés au sein du supercluster. Autrement dit, on cherche à exécuter les conteneurs algorithmiques dans les clusters appropriés.
Chaque cluster est gouverné par une solution jouant le rôle de planificateur/répartiteur de tâches et gestionnaire de conteneurs et de ressources physiques (ex : Yarn, Marathon, mais surtout Kubernetes). Aujourd’hui, tous les fournisseurs de cloud proposent des offres de type Kubernetes-as-a-service dans leurs clusters virtuels. La solution de DataOps doit aller un cran plus loin et jouer le rôle de “méta-orchestrateur”. Ce dernier vise à répartir les jobs parmi les orchestrateurs (Kubernetes) sous-jacents de chaque cluster. Le méta-orchestrateur est donc une couche d’abstraction additionnelle à Kubernetes. Lorsqu’une accélération quantique est nécessaire, le méta-orchestrateur est chargé de rediriger le conteneur algorithmique vers l’un des Kubernetes orchestrant les VM quantiques. Ainsi, le méta-orchestrateur s’assure du fait que seuls les jobs pertinents sont routés vers les VM quantiques, tandis que les autres peuvent s’exécuter on-premise ou sur des clusters clouds composés de VMs traditionnelles.
Quant aux problématiques de clusters HPC, il faut espérer la poursuite des développements d’interfaces entre Kubernetes et les ordonnanceurs de tâches sur grilles informatiques (ex : Slurm, IBM Spectrum LSF). Auquel cas, le méta-orchestrateur passera soit par Kubernetes (dans l’idéal), soit par l’ordonnanceur de grille HPC pour répartir sa charge.
En synthèse, l’essor des machines quantiques dans le cloud incitera les entreprises à optimiser la manière dont elles orchestrent leurs environnements analytiques et hybrides. Il s’agit avant tout d’une logique de souveraineté des données, de dépendance à des fournisseurs et de coûts (les calculs quantiques seront probablement très onéreux). L’interface DataOps, qui peut être une solution logicielle unifiée, est en particulier composée de quatre éléments : un outillage de CI/CD, un dépôt de fichiers partagés et de scripts, un virtualisateur de données et un méta-orchestrateur (en pratique, il faut aussi y adjoindre un dispositif de sécurité et un système de supervision globale). L’intérêt est triple : simplifier la gestion de données décentralisées, automatiser le déploiement de pipelines complexes et orchestrer le routage de certains codes lourds (compatibles au formalisme quantique) vers des clusters Kubernetes dotés de VM quantiques. Les entreprises seraient ainsi en mesure de gouverner leurs données en mode hybride, d’optimiser la répartition de charge et de contrôler leurs coûts (en particulier la facture cloud) en sollicitant les bons clusters au bon moment, en particulier lorsqu’il s’agit d’utiliser des serveurs HPC (ex : GPU, TPU, NPU, QPU, etc.).
____
Cet article fait partie d’une chronique dédiée à l’IA quantique. Retrouvez tous les posts du même thème :
Partie 1 – En finir avec l’impuissance !
Partie 2 – Faites vos jeux !
A. Augey
Publication relayée sur le blog de Saagie : https://www.saagie.com/fr/blog/ia-quantique-partie-4-le-role-cle-du-dataops/


